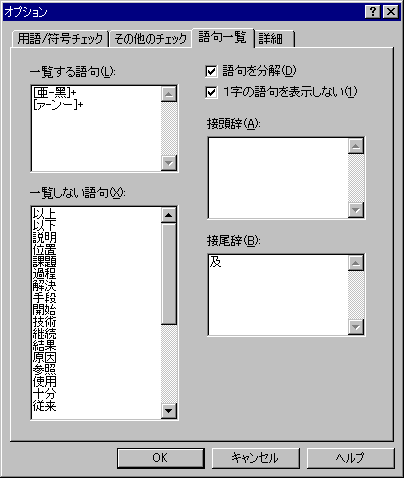
このタブでは、使用語句の一覧機能に関する設定を行います。
このダイアログボックスを表示するには、[チェック] メニューの [オプション] を選択し、[語句一覧] タブをクリックします。
一覧する語句
[使用語句の一覧] を実行したときに一覧する語句を正規表現で指定します。既定値は次のとおりで、これは漢字の連続とカタカナの連続の両方を一覧することを示します。
[亜-黑]+
[ァ-ンー]+
代表的な設定例を以下に示します。
| 設定 | 意味 |
|---|---|
| [亜-黑]+
[ァ-ンー]+ | 漢字の連続とカタカナの連続を一覧 (既定値) |
| [亜-黑]+ | 漢字の連続だけを一覧 |
| [ァ-ンー]+ | カタカナの連続だけを一覧 |
| [亜-黑ァ-ンー]+ | 漢字とカタカナが混在する文字列を一覧 |
| [亜-黑]+[ァ-ンー]* | 1つ以上の漢字の後に0個以上のカタカナが続く文字列を一覧 |
一覧しない語句
このボックスに指定した語句は、上の [一覧する語句] にヒットしても表示されません。つまり、余計な語句の表示を抑制することができます。各語句は改行で区切って正規表現で指定します。
漢字の語句を一覧
文書中で使用されている漢字語を一覧表示します。連続する漢字の塊が機械的に検出されます。たとえば、左記の文からは、「連続」「漢字」「塊」「機械的」「検出」の 5 つの語句が検出されます。
語句を分解
2 つ以上の語句に分解できる語句を表示しません。たとえば、「記録」、「判定」、「機器」、という語句が文書中に存在する場合、「記録判定」、「判定記録」、「記録判定機器」などの表示は抑制されます。
文書中に存在しない語句を一部にでも含む語句は、表示されます。たとえば、「記録」と「判定」が文書中に存在しても、「機器」が存在しなければ、「記録判定機器」の表示は抑制されません。
1 文字の語句は分解先として使用されません。たとえば、「記録」と「機」が文書中に存在しても、「記録機」は表示されます。この規則があるのは、必要以上に多くの語句の表示を抑制しないためです。
1 字の語句を表示しない
1 字の漢字語句には検出しても無意味なものが多いため、この制限オプションが用意されています。
接頭辞
検出された語句の先頭が、このボックスに指定された文字列と一致すると、その先頭部分が削除されます。たとえば、ここに「前」を指定しているときに「前世紀」が検出されると、「世紀」という語句が検出されたものと見なされます。
接尾辞
上と同様に、検出された語句の末尾が、このボックスに指定された文字列と一致すると、その末尾部分が削除されます。たとえば、ここに「及」を指定しているときに「鋼体及(び)」が検出されると、「鋼体及」ではなく「鋼体」という語句が検出されたことになります。